通知公告
-
详细议程|第四届“数字法治与智慧司法”国际研讨会暨湖北省法学会法理学研究会2024年年会
-
会议议程丨中国法学会网络与信息法学研究会2024年年会暨第二届数字法治大会会议议程
-
会议通知 | 四川省法学会人工智能与大数据法治研究会会员大会暨2024年年会通知
-
征文启事丨CCF中国计算法学研讨会暨第三届学术年会征文启事
-
会议议程丨网络与信息法学学科建设论坛
-
获奖名单|第二届“法研灯塔”司法大数据征文比赛获奖名单出炉啦!
-
讲座信息|王竹:数据产权的民法规制路径
-
会议议程 | 四川省法学会人工智能与大数据法治研究会2023年年会暨“人工智能与数据法律风险研讨会”
-
会议议程|11.04 中国民商法海南冬季论坛——数据法学的当下和未来
-
讲座信息|王竹:数据产品的民法规制路径
新闻|LAIW第2期活动暨“法律大数据分析”课程第二次行课 ——三步理清深度学习
时间:2018-10-10![]()
2018年10月10日下午13:50,由四川大学计算机学院、数学学院、法学院联合开办的“法律大数据分析”课程第二次专题研讨课在四川大学江安校区顺利开课。计算机学院张意副教授主要从计算机应用角度出发深入浅出地介绍了深度学习(Deep Learning)。

深度学习是一个近几年来十分火热的计算机研究方向。提到深度学习,与它相关的其他概念,例如机器学习、人工智能,常常会让人难以辨明。从应用的时间线和概念范畴进行比对,深度学习是机器学习的一个子集,而机器学习则是涵盖在人工智能之内。

具体而言,机器学习可以约等于寻找适合的函数。例如输入一段语音,需要函数具有识别声音波段的功能来输出识别的反馈内容。因此,机器学习的流程大致可以划分为三步:第一步,通过大量前期人工处理的数据,定义函数集合,建立模型;第二步,定义一个标准寻找函数的优劣;第三步,再通过监视学习作为验证模型的评价标准,找出最优模型。深度学习的流程与机器学习不同之处在于,第一步建立的是神经元网络模型。
神经网络模型是一种仿生人脑的神经元而建立的模型,模型结构的原理是仿真人的神经元受刺激的过程。其中,以向量(Neuron)仿真神经元核心,以添加不同参数、权重等仿真人脑受到刺激的过程。神经网络模型从本质上讲就是函数集。仿真的神经元结构搭建出函数框架(Function Set),再根据训练数据(Training Data)确定定义的学习目(Learning Target)添加参数、权重、偏移,最终通过不同的验证方式找出最优模 。
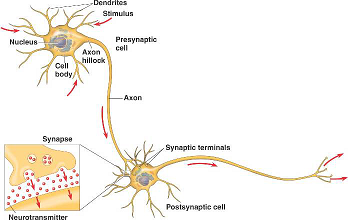

为什么通过神经网络模型找出最优函数的方式会被称为“深度学习”?这里需要对“深度”(Deep)进行解释。深度是指输入层和输出层之间的众多层数,一般三层以上的神经网络可以称为使用了深度学习方法。那么,这样多层设计结构有什么优势呢?目前存在一个已经被证明的结论:数学上的任何一个函数都可以用一层神经网络实现。但是仅用一层神经网络解决复杂问题,那这个网络会异常庞大。神经网络模型增加层数的方式比之一层网络增加参数的方式,有着减少参数和数据量的优点。在图片识别领域,伴随着层数的增加,识别的精准度也会提高。

深度学习的第二步是定义函数优劣的标准。这里引用一个概念Loss,是指输出结果和目标结果之间的差距。评判的标准就是使得总的Loss尽可能小的函数可能就是好的函数。
张意老师认为,深度学习的难点在于第三步流程。其中,参数的调整需要耗资较高的设备支撑。参数的调整,在深度学习领域,目前大多使用的是梯度下降法:通过寻找函数梯度的地方,求取局部函数最小值。具体是先随机挑选初始值,再对一个或者多个参数W进行求导。由于随机挑选的初始值不同,可能出现一个局部函数极值,因此需要调整参数不断尝试。对此张意老师的说法是,如何确定网络结构的层数和参数,都是需要依靠在调试过程中不断积累的试错经验和个人灵光闪现的直觉。
深度学习的概念其实很早就已经出现。最初由于层数达到3层时不可避免地出现梯度爆炸、梯度弥散等问题,导致深度学习的研究一度停滞。直到2006年新的分层计算方法出现,深度学习的发展迎来了曙光。现如今,深度学习的应用越发广泛,从图像识别、垃圾邮件过滤、新闻分类,发展到了风格迁移、结合对抗学习、图片问答等领域。其中,最广为人知的应用典型就是根据对抗神经网络和强化学习结合的思路设计而成的阿尔法Go。深度学习与法律的结合场景,主要在庭审过程中识别法官、检察官、诉讼参与人等主体的行为是否符合法庭纪律。这里运用到深度学习中多模态图像转化和图像、视频识别等技术,来观察这些主体是否有使用手机、争吵等行为并进行相应的反馈。此外,张意老师还在课堂上展现了用Keras编写的模型是如何识别手写数字的具体步骤。欢迎大家下载课件学习、尝试。
